*요새 바빠서 업로드가 늦어지고 있네요 ㅠㅠ 후에 나올 분석이나 결과가 궁금하신 분들은 댓글 부탁드립니다. 원하시는 분이 있으시면 서둘러 노력해서 업로드 하겠습니다.
2019년 2학기 가톨릭대학교 '어드벤쳐 디자인 : Bussiness Analysis' 프로젝트 수업 주제로 영화 데이터 분석을 정했습니다. 데이터를 수집하며 고민해본 결과 영화 수익률을 목표 변수로 한 3종류의 회귀 분석을 진행하게 되었습니다. 이에 대한 포스팅을 순차적으로 하면서 했던 고민과 분석 결과, 결과 시각화를 공유하고자 합니다.
데이터 셋 파일과 작업 노트북 파일은 https://github.com/jaylee4274/Korean-Movie-data-analysis 에 공유합니다.
모든 작업은 구글 코랩환경(Python3)에서 진행했습니다.
(1) 데이터 수집
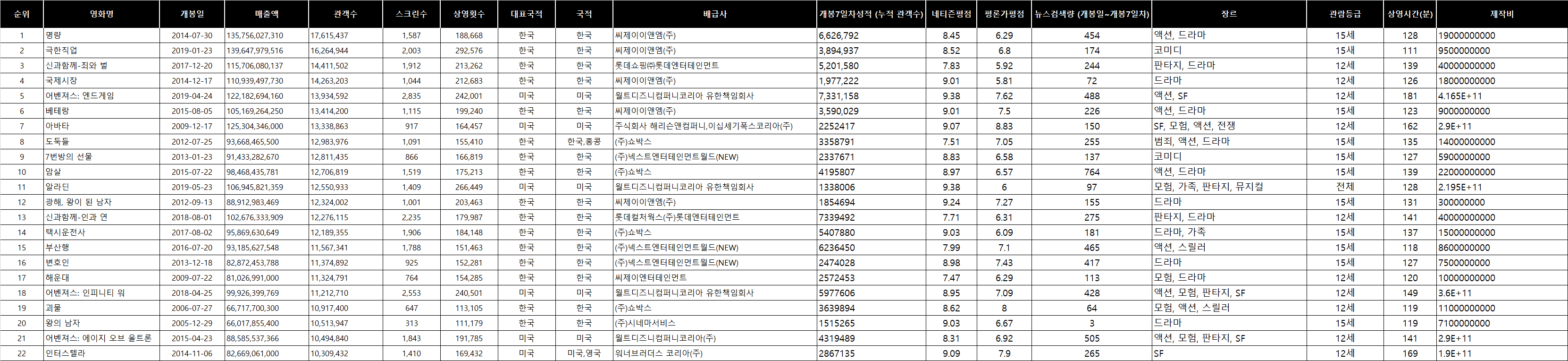
데이터는 영화진흥위원회(KOFIC) 사이트의 영화관입장권통합전산망을 이용해 역대 박스오피스 200위까지의 데이터를 엑셀 형식으로 받아 기본 틀을 잡았습니다. http://www.kobis.or.kr/kobis/business/stat/boxs/findFormerBoxOfficeList.do
여기에 다른 선행 연구들에서 보였던 변수들을 몇 가지 추가해 200행의 데이터셋을 완성했습니다. 그 변수들은 다음과 같습니다.
추가 변수 : 개봉 7일차 누적 관객수, 네티즌 평점, 평론가 평점, 개봉 7일차 뉴스검색량, 제작비
(2) 데이터 셋 가공(엑셀)
데이터가 크지 않아 간단한 전처리나 가공 작업은 엑셀에서 손으로 했습니다.
1) 변수명을 분석에 용이하게 영문자로 바꿨습니다.
(차례대로) 수입, 비용, 스크린 수, 상영횟수, 첫 주 성적, 평점, 전문가 평점, 첫 주 영화 뉴스량, 최종 관객수, 영화길이, 수익률(수입/비용)입니다.
2) 분석에 사용할 변수만 남겼습니다.
범주형 변수들을 분석에 사용하려고 했더니 배급사, 장르 같은 부분은 종류가 워낙 많아 변수 인코딩을 해도 어떻게 사용해야 할지 잘 모르겠어서 제외했습니다. 관람등급은 12세, 15세, 청불 3가지로 분석에 사용한 결과 수익률에 영향을 유의미하게 주지 않는다고 판단해 제외했습니다.

3) 수익률 기준 이상치를 제거했습니다.
작업을 하다보니 roi 수치가 비정상적으로 높은, 그러니까 제작비에 비해 엄청난 수입을 거둔 영화가 있었습니다. 바로 '워낭소리'와 '님아 그 강을 건너지 마오'인데요 여러분들도 잘 아실만한 저예산 영화로 roi값이 250을 상회해 분석에서 제외했습니다.
(3) 데이터 불러오기
Colab에서 데이터를 import하는 방법에는 2가지가 있습니다. 첫 번째는 파일탭에 불러올 파일을 드래그앤드랍 해서 경로복사 하는방법, 두 번째는 드라이브 마운트로 Google drive에 업로드한 파일의 경로복사해서 import 하는 것 입니다. 저는 두번째 방법을 사용했습니다.
1) 파일탭의 드라이브 마운트 실행

저 탭의 코드를 실행하고 아래의 링크로 가서 절차를 진행하고, 아래의 빈칸에 인증코드를 복사 붙여넣기 하면 완료입니다. 그렇게 하면 본인의 Google Drive의 파일들의 경로를 불러다가 사용할 수 있습니다.
2) 경로 복사하기
저 같은 경우 아래와 같은 경로에서 불러올 파일을 찾을 수 있었습니다. 우클릭 후 경로 복사로 drive상의 경로를 찾아줍니다.

3) 불러오기
movie1 = pd.read_excel('/content/drive/My Drive/My Notebooks /어드벤쳐디자인/rawdata_ver1.09(trunc).xlsx')
movie = movie1.dropna()
movie.head()저는 경로가 위와 같이 나와 이렇게 불러왔습니다. dropna()는 분석 과정에서 오류를 잡느라 했던 것 같습니다.
이번 글에서는 분석을 위한 준비 단계, Colab 환경에서 불러오기 환경 설정하는 법 등을 다뤘습니다. 다음 포스팅에서는 변수간 상관관계 탐색 - 시각화를 위의 데이터를 가지고 해보겠습니다. 감사합니다. :D
'Python > 영화 데이터 분석' 카테고리의 다른 글
| 한국 영화 데이터 분석 (2) : 탐색적 자료 분석(EDA)과 상관 시각화 Google Colab Python (0) | 2020.07.24 |
|---|

댓글