반응형

본 논문은 2016년에 딥마인드에서 발표한 PER의 후속 논문으로 기존 PER과 대동소이하지만 제목에서 알 수 있듯이 데이터 분산처리라는 세팅에서 수행되었다는 점이 차이점입니다. 당시의 트렌드가 무거운 모델, 더 많은 데이터를 필요로 함에 따라 적절한 분산 처리를 통해 scalability를 확장하는 것이 중요한 과제였고 그에 따라 위와 같은 연구가 진행되었습니다.
목차





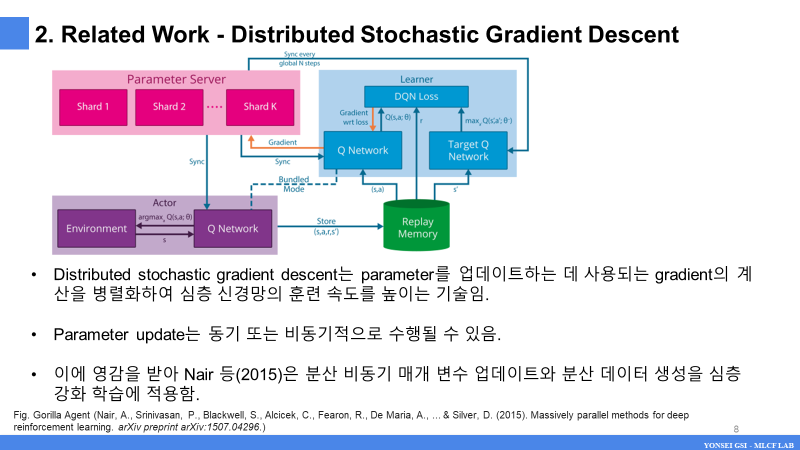
- Gorila 에이전트는 learner, actor 및 매개 변수 서버를 분리하여 train process를 병렬화합니다. 단일 실험에서 여러 학습자 프로세스가 존재하며 지속적으로 파라미터 서버로 그래디언트를 보내고 업데이트된 파라미터를 수신합니다.
- 동시에, 독립된 actor는 병렬로 경험을 축적하고 매개변수 서버에서 Q-네트워크를 업데이트할 수도 있습니다.





- 여러 actor 가 각각 고유한 환경에서 경험을 생성하고 이를 shared experience replay memory에 추가하며 데이터의 초기 우선순위를 계산합니다.
- 단일 Learner는 이 메모리에서 샘플을 추출하여 네트워크 및 메모리에서 경험의 우선 순위를 업데이트합니다.
- Actor의 네트워크는 learner에서 얻어진 파라미터로 주기적으로 업데이트 됩니다.


Actor와 Learner가 분리되어 각 Actor는 learner의 buffer에 Local buffer를 sampling 해서 처리해 넣고, learner는 그 buffer를 이용해 update 하는 형식으로 주목할만한 점은 다음 세 가지로
- Actor는 local buffe를 가진다는 것과
- 두 번째로 Centralized memory(replay memory)에 보내기 전에 priorities를 계산해 넣는다,
- 그리고 마지막으로 주기적으로 learne의 paramete로 updat 함으로써 2번에서 넣는 priorities가 learner가 계산하는 priorities와 크게 차이 나지 않게 계속 얻어질 수 있다는 점입니다.



- 우리는 정책과 Q-네트워크 파라미터를 각각 φ(파이)와 ψ(프시)로 나타내며, 대상 네트워크는 위의 DQN처럼 표기 정책 매개 변수는 gradient q(St , π, ψ)를 사용하여 예상 Q-값의 정책 그레이디언트 상승방법을 사용하여 업데이트됩니다.
- 확정적 정책을 가지는, DDPG는 이전 정책에서 발생한 궤적으로 업데이트되는 off-policy 방식
- 크리틱 신경망은 액터 신경망이 계산한 행동과 상태변수를 입력으로 받아서 타깃 액터 신경망(Target actor network)과 타깃 크리틱 신경망(Target critic network)을 별도로 운영함.



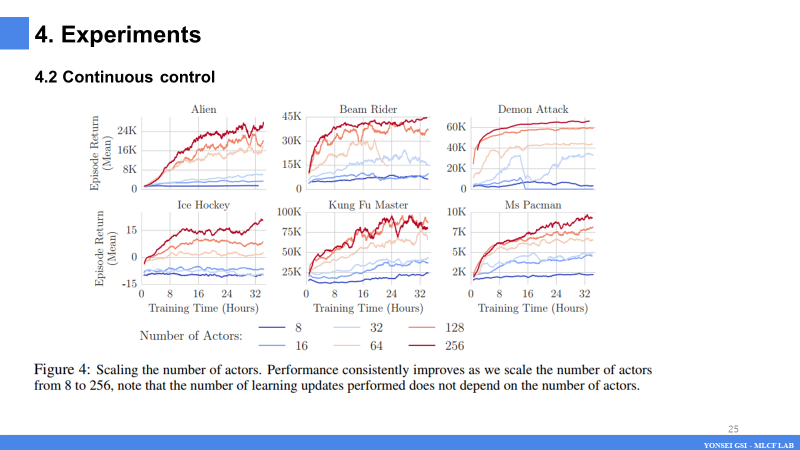
- 왼쪽 그림 2에서는 57개 게임 모두에서 인간 기준에 정규화된 점수를, 다시 말해 100 이상이면 인간 수준 이상임을 의미합니다.
- DQN, 우선순위 DQN, 분포 DQN(Bellemare et al., 2017), 레인보우 및 고릴라 등의 여러 기준선과 비교합니다.
- 모든 경우에 성능은 no-op starts 시험 체제 하에서 훈련 종료 시 측정됩니다.(no-ops란 게임 시작 초기 일정 시간 동안 조작을 하지 않는 환경 설정을 의미)
- 오른쪽에는 6개의 게임(모든 게임에 대한 전체 학습 곡선은 부록에 있음)의 선택에 대한 초기 학습 곡선(가장 greedy 한 actor에게서 따옴)을 보여줍니다.
- Ape-X가 대부분의 기준선보다 훨씬 더 많은 계산을 사용할 수 있다는 점을 고려하면, 더 빠르게 훈련될 것으로 기대할 수 있습니다. 그림 2는 이것이 실제로 그랬다는 것을 보여줍니다.
- 논문에서 제시하는 에이전트는 훨씬 더 높은 성과를 달성했습니다.
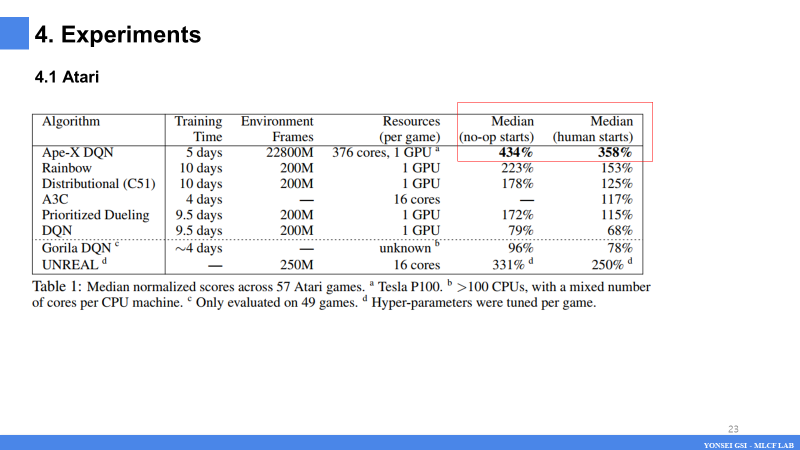
- 표 1에서는 Atari 벤치마크에서 Ape-X DQN의 인간 정규화 성능을 해당 퍼블리케이션 라이선스의 다른 기준 에이전트에 대해 보고된 해당 메트릭과 비교합니다.
- 가능한 경우 언제든지 no-op 시작 및 인간 시작에 대한 결과를 보고합니다. 인간 시작 체제(Nair et al., 2015)는 에이전트가 인간 전문가가 수행한 게임에서 추출한 무작위 시작에서 초기화되기 때문에 더 어려운 일반화 테스트에 해당합니다. Ape-X의 성능은 두 메트릭 모두에서 기준선의 성능보다 높습니다.
- No-op 시작 설정에서 에이전트는 에피소드 시작 시 최대 30회까지 "아무것도 안 함" 작업을 선택합니다. 이는 에이전트에 임의의 시작 위치를 제공합니다.
- 인간 시작 설정에서 에이전트는 인간 전문가의 게임 플레이에서 샘플링된 100개의 시작 지점 중 하나에서 시작합니다.
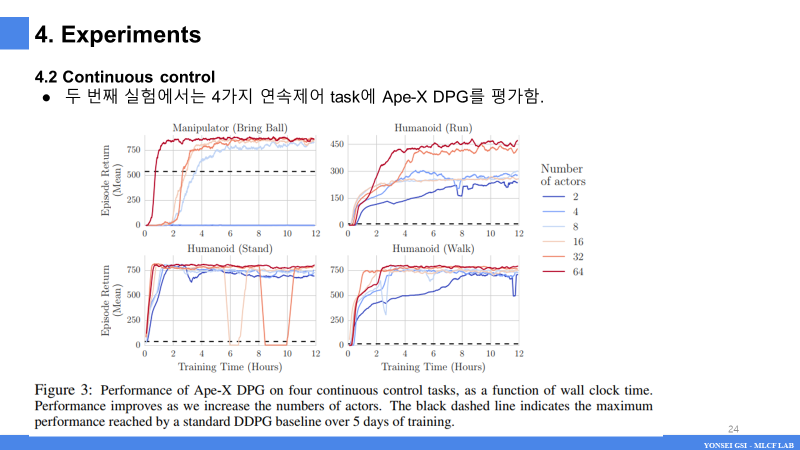
- 그림 3은 Ape-X DPG가 4가지 작업 모두에서 매우 우수한 성과를 달성했음을 보여줍니다.
- 그림에는 다양한 actor 수에 대한 Ape-X DPG의 성능이 나와 있습니다.
- actor 수가 증가함에 따라 에이전트가 이러한 문제를 빠르고 안정적으로 해결하는 데 점점 더 효과적이 되어 10배 이상 더 오랫동안 훈련된 표준 DDPG 기준선을 형성한다. 병렬 논문(Barth-Maron et al., 2018)은 Ape-X DPG와 분포 가치 함수를 결합하여 이 작업을 기반으로 하며, 결과 알고리즘이 추가 연속 제어 작업에 성공적으로 적용됩니다.




반응형
댓글